Sequence Viewer
Sequence Viewer is designed to display and edit primarily protein sequences. Sequences can be loaded directly from files in CLUSTALW .aln or FASTA formats. More formats will be added shortly. Also, when s structure is loaded in the 3D component, its sequence is automatically displayed in the sequence viewer. Yet another way to load sequences is by using data access component that can carry out searches in remote databases. Once a set of sequences is returned, the user may select and load them into the viewer.
When a protein sequence is derived from a structure, bound water molecules are denoted by * symbols, while other ligands are shown as # symbols. Individual residues can be selected by clicking. Holding a control key while clicking allows for selection of multiple residues.
Sequences can be marked for various actions (input for database search ir statistics analyses) by clicking the name panel. Columns can be selected by clicking column header panel. The header also shows residue numbering, which is adjusted to the currently selected sequence. If there are gaps in the chain, the numbering reflects it. In addition, the user may choose to use residue tips, which are transiently displayed labels showing residue name and number (e.g., PHE120), as they are recorded in the source file.
Right-clicking on a name panel of a sequence brings up a popup menu with the following options: rename sequence, move it to the top of the alignment, bottom of the alignment, hide from the display or remove. Right-clicking on the corner button of the viewer brings up a popup menu with options to show all sequences, hide all sequences, hide only marked sequences or save the displayed alignment.
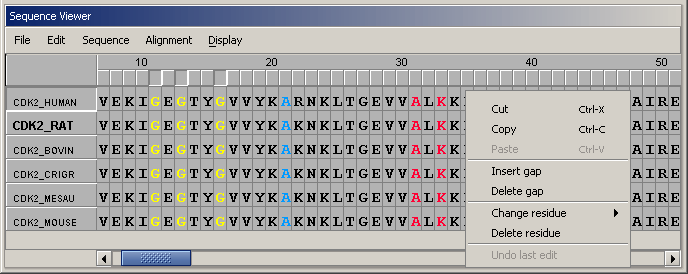
The sequence viewer also supports editing capabilities. Editing mode is enabled through the Edit menu. The menu provides options for dealing with gapped columns and gives access to the undo functions. Right-clicking on a residue in the display brings up a popup menu with more specific options: cut or copy clicked or selected residue(s) from the display, paste into the sequence at the point of the click; insert or delete a gap. In addition, it is possible to "mutate" or replace an amino acid residue or delete it from the sequence. If one of these two actions is selected, the change is reflected in the structure display, if there is a structure associated with the edited sequence.
Further topics: menu options
| Display options | Includes display and selection options |
| File operations | Basic file operations for a protein sequence |
| Statistics | Displays statistics based on side chain distribution |
| Editing | Adding and removing gapped columns |